In my previous post, I tried to build a map of the Kanjis. The result was barely useful, and not very satisfying. Since then, I've been pointed out various other interesting Kanji learning sources, but very few graphing solutions.
After trying Springy.js, it appeared that 2D was too limited for what I wanted to achieve.
That's when I came across a pretty awesome software, UbiGraph. I recommend having a look to the demos, it's really simple to use, faster than the other 2D solutions I tried, and well, the positioning of the nodes is working just as expected. That last point may sound obvious, but that was the main issue I had with Graphviz.
Unfortunately, I quickly had to face two main issues:
- The node labels do not support Unicode, which is quite troublesome for a Kanji map
- It is closed source
Since I wanted to try that engine anyway, I decided to come up with a hack to support Unicode. The complete source code of the hack is linked at the end of the article.
Hook into the server
First, just a summary on how that software works. It's essentially a server
(bin/ubigraph_server) which spawns a black OpenGL window. Then you have the
possibility with various language interfaces to connect to it and add nodes and
links. After each operation the server window gets updated and you can dive
into your graph.
Now the idea is to have such code working:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
server = xmlrpclib.Server('http://localhost:20738/RPC2')
G = server.ubigraph
G.clear()
vrtx = G.new_vertex()
G.set_vertex_attribute(vrtx, 'label', '好')
Looking at the ubigraph_server binary, we can guess that what is used to
display the text labels is the glutBitmapCharacter function:
% readelf -s bin/ubigraph_server|grep glutBitmap
69: 0000000000000000 241 FUNC GLOBAL DEFAULT UND glutBitmapCharacter
287: 00000000007d1520 24 OBJECT GLOBAL DEFAULT 27 glutBitmapHelvetica12
292: 00000000007d1180 24 OBJECT GLOBAL DEFAULT 27 glutBitmapHelvetica18
305: 00000000007d1300 24 OBJECT GLOBAL DEFAULT 27 glutBitmapTimesRoman24
306: 00000000007d1320 24 OBJECT GLOBAL DEFAULT 27 glutBitmapTimesRoman10
326: 00000000007d11a0 24 OBJECT GLOBAL DEFAULT 27 glutBitmapHelvetica10
In freeglut 2.8.1, the function is defined as such
(src/freeglut_font.c):
/*
* Draw a bitmap character
*/
void FGAPIENTRY glutBitmapCharacter( void* fontID, int character )
{
const GLubyte* face;
SFG_Font* font;
FREEGLUT_EXIT_IF_NOT_INITIALISED ( "glutBitmapCharacter" );
font = fghFontByID( fontID );
freeglut_return_if_fail( ( character >= 1 )&&( character < 256 ) );
freeglut_return_if_fail( font );
/*
* Find the character we want to draw (???)
*/
face = font->Characters[ character ];
glPushClientAttrib( GL_CLIENT_PIXEL_STORE_BIT );
glPixelStorei( GL_UNPACK_SWAP_BYTES, GL_FALSE );
glPixelStorei( GL_UNPACK_LSB_FIRST, GL_FALSE );
glPixelStorei( GL_UNPACK_ROW_LENGTH, 0 );
glPixelStorei( GL_UNPACK_SKIP_ROWS, 0 );
glPixelStorei( GL_UNPACK_SKIP_PIXELS, 0 );
glPixelStorei( GL_UNPACK_ALIGNMENT, 1 );
glBitmap(
face[ 0 ], font->Height, /* The bitmap's width and height */
font->xorig, font->yorig, /* The origin in the font glyph */
( float )( face[ 0 ] ), 0.0, /* The raster advance -- inc. x,y */
( face + 1 ) /* The packed bitmap data... */
);
glPopClientAttrib( );
}
After a few tests, it was confirmed that this function was called with
character taking the value of 0xe5, 0xa5 and 0xbd; basically the UTF-8
encoded 好.
This function then lookups into hardcoded character tables and display the
character with a glBitmap() call, which also moves the raster position for
the next character.
In order to make this function supports UTF-8, a few hacks were required.
First, we need to redefine this function. The most simple way of achieving this
is obviously to use LD_PRELOAD to point on a kanjimod.so redefining the
glutBitmapCharacter function.
Unicode reconstruction
The second step was to reconstruct the UTF-32 code with the provided character
byte by byte. The simplest way of doing this is just to abuse various static
variables into the function context.
It looks like this (code heavily based on FFmpeg's code):
void glutBitmapCharacter(void *font, int character)
{
static uint32_t val;
static uint32_t top;
static int wait_next_char;
static int wait_close_bracket;
static int pic_id;
uint8_t chr = character;
/* re-construct utf-32 codes */
if (wait_next_char) {
const int tmp = chr - 128;
if (tmp >> 6)
goto err;
val = (val << 6) + tmp;
top <<= 5;
} else {
val = chr;
if ((val & 0xc0) == 0x80 || val >= 0xfe)
goto err;
top = (val & 128) >> 1;
}
wait_next_char = (val & top);
if (!wait_next_char)
val &= (top << 1) - 1;
// [...]
err:
fprintf(stderr, "Invalid utf-8 byte code %02x\n", chr);
val = top = wait_next_char = 0;
}
At this point, val contains the UTF-32 character code. Next, we need a
rasterizer to get the glyph bitmap to blend. The most obvious choice was to use
FreeType.
FreeType
Instead of using a static for the FreeType initialization state in
glutBitmapCharacter(), I decided to add a hook on glutInit():
#define _GNU_SOURCE 1
#include <dlfcn.h>
#include <stdio.h>
static FT_Library library;
static FT_Face face;
void glutInit(int *argcp, char **argv)
{
void (*orig_glutInit)(int*, char**) = dlsym(RTLD_NEXT, "glutInit");
orig_glutInit(argcp, argv);
printf("Init FT library\n");
if (FT_Init_FreeType(&library)) {
fprintf(stderr, "FT init error\n");
return;
}
if (FT_New_Face(library, "/usr/share/fonts/TTF/HanaMinA.ttf", 0, &face)) {
fprintf(stderr, "FT font face load error\n");
return;
}
if (FT_Set_Char_Size(face, 0, 8<<6, 300, 300)) {
fprintf(stderr, "FT set char size error\n");
return;
}
}
Rendering the characters
To display the characters, I kept most of the GL code from the original
glutBitmapCharacter(). Basically, no anti-aliasing, and thus using a 1 bit
per pixel bitmap. Following is the relevant code:
FT_GlyphSlot slot;
FT_Bitmap *bitmap;
uint8_t buf[4096];
int w, h, advance, x_start, y_start, y, ft_pitch, gl_pitch;
glPushClientAttrib(GL_CLIENT_PIXEL_STORE_BIT);
glPixelStorei(GL_UNPACK_SWAP_BYTES, GL_FALSE);
glPixelStorei(GL_UNPACK_LSB_FIRST, GL_FALSE);
glPixelStorei(GL_UNPACK_ROW_LENGTH, 0);
glPixelStorei(GL_UNPACK_SKIP_ROWS, 0);
glPixelStorei(GL_UNPACK_SKIP_PIXELS, 0);
glPixelStorei(GL_UNPACK_ALIGNMENT, 1);
if (FT_Load_Char(face, utf32char, FT_LOAD_RENDER|FT_LOAD_TARGET_MONO)) {
fprintf(stderr, "FT loading/rendering char error\n");
break;
}
slot = face->glyph;
bitmap = &slot->bitmap;
w = bitmap->width;
h = bitmap->rows;
/* freetype insanity, not even working properly in all cases yet */
advance = slot->advance.x >> 6;
x_start = advance - slot->bitmap_left;
y_start = h - slot->bitmap_top;
/* freetype and opengl bitmap linesizes may mistmatch; typically in
* the case of of a very thin characters such as "l", ",", "'". */
ft_pitch = bitmap->pitch;
gl_pitch = (w + 7) >> 3; // up-rounded div by 8
/* reverse bitmap (GL has the y origin on the bottom) */
for (y = 0; y < h; y++)
memcpy(buf + y*gl_pitch, bitmap->buffer + (h-y-1)*ft_pitch, gl_pitch);
glBitmap(w, h, x_start, y_start, advance, 0, buf);
glPopClientAttrib();
With such code I was able to achieve the main purpose of the hack:
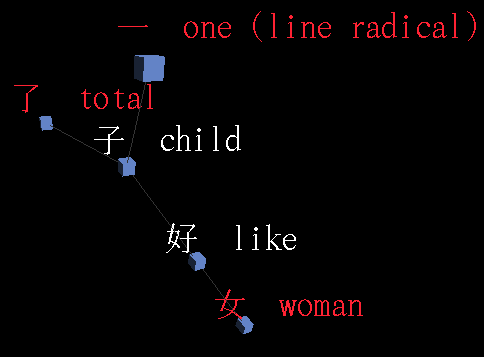
A better database
In the previous post, I was using some official Kanjis dictionaries. While they are pretty complete, they kind of lack some educational properties. So in order to improve the usefulness of the output, I decided to rely on Kanji Damage database.
Of course, extracting the database from the website was a bit boring work. I did exactly what good programmers tend to dislike: use shell scripts and regex to parse HTML and extract the content. And I don't give a fuck.
The database order of the Kanjis is relevant for educational purposes. The
author also added "invented" radicals that don't actually exists but greatly
help the learning. Those radicals, such as the standing
worms don't have a matching character, so we can't
use FreeType to render them in the graph. To add the picture support, the code
was adjusted to replace strings such as [69] with the appropriate bitmap. The
bitmap table is generated using a simple python script opening the PNG files
from the site and generating C code.
Demo
Here is a demo of the mod in action (without the English translations to avoid a too cluttered output):
In red the radicals, in green the invented radicals, and in white the remaining Kanjis.
The full code of the mod and the instructions on how to use it are available on my GitHub.