It's been a very long time since I've done some actual reverse engineering work. Going through a difficult period currently, I needed to take a break from the graphics world and go back to the roots: understanding obscure or elementary tech stuff. One may argue that it was most certainly not the best way to deal with a burnout, but apparently that was what I needed at that moment. Put on your black hoodie and follow me, it's gonna be fun.
The beginning and the start of the end
So I started solving a few crackmes from crackmes.one to get a hang of it. Most were solved in a relatively short time window, until I came across JCWasmx86's cm001. I initially thought the most interesting part was going to be reversing the key verification algorithm, and I couldn't be more wrong. This article will be focusing on various other aspects (while still covering the algorithm itself).
The validation function
After loading the executable into Ghidra and following the entry
point, we can identify the main function quickly. A few renames later we
figure out that it's a pretty straightforward function (code adjusted manually
from the decompiled view):
int main(void)
{
char input[64+1] = {0};
puts("Input:");
fgets(input, sizeof(input), stdin);
validate_input(input, strlen(input));
return 0;
}
The validate_input() function on the other hand is quite a different beast.
According to the crackme description we can expect some parts written in
assembly. And indeed, it's hard to make Ghidra generate a sane decompiled code
out of it. For that reason, we are going to switch to a graph view
representation.
I'm going to use Cutter for… aesthetic reasons. Here it is, with a few annotations to understand what is actually happening:

To summarize, we have a 64 bytes long input, split into 4 lanes of data, which are followed by a series of checks. This flow is very odd for several reasons though:
- We don't see any exit here: it basically ends with a division, and all other
exits lead to
failed_password(the function that displays the error). What we also don't see in the graph is that after the last instruction (div,Oddity #1), the code falls through into thefailed_passwordcode, just like the other exit code paths - We see an explicit check only for the first and second lanes, the 2 others
are somehow used in the division, but even there, only slices of them are
used, the rest is stored at some random global location (in the
.bss, at0x4040b0and0x4040a8respectively) - 128 bits of data are stored at
0x4040b0(Oddity #0): we'll see later why this is strange
The only way I would see this flow go somewhere else would be some sort of
exception/interruption. Looking through all the instructions again, the only
one I see causing anything like this would be the last div instruction, with
a floating point exception. But how could that even be caught and handled, we
didn't see anything about it in the main or in the validate function.
At some point, something grabbed my attention:
Relocation section '.rela.plt' at offset 0x598 contains 6 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000404018 000100000007 R_X86_64_JUMP_SLO 0000000000000000 puts@GLIBC_2.2.5 + 0
000000404020 000200000007 R_X86_64_JUMP_SLO 0000000000000000 write@GLIBC_2.2.5 + 0
000000404028 000300000007 R_X86_64_JUMP_SLO 0000000000000000 strlen@GLIBC_2.2.5 + 0
000000404030 000500000007 R_X86_64_JUMP_SLO 0000000000000000 fgets@GLIBC_2.2.5 + 0
000000404038 000600000007 R_X86_64_JUMP_SLO 0000000000000000 signal@GLIBC_2.2.5 + 0
000000404040 000800000007 R_X86_64_JUMP_SLO 0000000000000000 exit@GLIBC_2.2.5 + 0
There is a signal symbol in the relocation section, so there must be code
somewhere calling this function, and it must certainly happens before the
main. Tracing back the function usage from Ghidra land us here (again, code
reworked from its decompiled form):
void _INIT_1(void)
{
signal(SIGFPE, handle_fpe);
return;
}
But how does this function end up being called?
Program entry point
At this point I needed to dive quite extensively into the Linux program startup procedure in order to understand what the hell was going on. I didn't need to understand it all during the reverse, but I came back to it later on to clarify the situation. I'll try to explain the best I can how it essentially works because it's probably the most useful piece of information I got out of this experience. Brace yourselves.
Modern (glibc ≥ 2.34, around 2018)
On a Linux system with a modern glibc, if we try to compile int main(){return 0;} into an ELF binary (cc test.c -o test), the file crt1.o (for Core
Runtime Object) or one of its variant such as Scrt1.o (S for "shared") is
linked into the final executable by the toolchain linker. These object files
are distributed by our libc package, glibc being the most common one.
They contain the real entry point of the program, identified by the label
_start. Their bootstrap code is actually fairly short:
% objdump -d -Mintel /usr/lib/Scrt1.o
/usr/lib/Scrt1.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <_start>:
0: f3 0f 1e fa endbr64
4: 31 ed xor ebp,ebp
6: 49 89 d1 mov r9,rdx
9: 5e pop rsi
a: 48 89 e2 mov rdx,rsp
d: 48 83 e4 f0 and rsp,0xfffffffffffffff0
11: 50 push rax
12: 54 push rsp
13: 45 31 c0 xor r8d,r8d
16: 31 c9 xor ecx,ecx
18: 48 8b 3d 00 00 00 00 mov rdi,QWORD PTR [rip+0x0] # 1f <_start+0x1f>
1f: ff 15 00 00 00 00 call QWORD PTR [rip+0x0] # 25 <_start+0x25>
25: f4 hlt
If we look closely at the assembly above, we notice it's a skeleton with a few
placeholders. More specifically the call argument and the rdi register just
before. These are respectively going to be replaced at link time with a call to
the __libc_start_main() function, and a pointer to the main function. Using
objdump -r clarifies these relocation entries:
18: 48 8b 3d 00 00 00 00 mov rdi,QWORD PTR [rip+0x0] # 1f <_start+0x1f>
1b: R_X86_64_REX_GOTPCRELX main-0x4
1f: ff 15 00 00 00 00 call QWORD PTR [rip+0x0] # 25 <_start+0x25>
21: R_X86_64_GOTPCRELX __libc_start_main-0x4
Note that __libc_start_main() is an external function: it is located inside
the glibc itself (typically /usr/lib/libc.so.6).
Said in more simple terms, what this code is essentially doing is jumping
straight into the libc by calling __libc_start_main(main, <a few other args>). That function will be responsible for calling main itself, using the
transmitted pointer.
Why not call directly the main? Well, there might be some stuff to initialize
before the main. Either in externally linked libraries, or simply through
constructors.
Here is an example of a C code with such a construct:
#include <stdio.h>
__attribute__((constructor))
static void ctor(void)
{
printf("ctor\n");
}
int main()
{
printf("main\n");
return 0;
}
% cc test.c -o test && ./test
ctor
main
In this case, a pointer to ctor is stored in a table in one of the ELF
section: .init_array. At some point in __libc_start_main(), all the
functions of that array are going to be called one by one.
With this executable loaded into Ghidra, we can observe this table at that particular section:
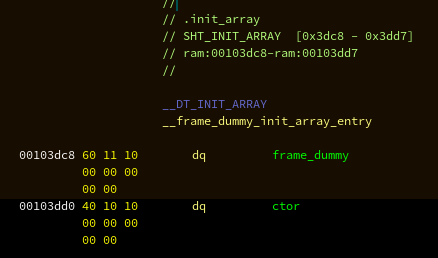
So basically a table of 2 function pointers, the latter being our custom ctor
function.
The way that code is able to access the ELF header is for another story.
Similarly, even though related, I'm going to skip details about the dynamic
linker. I'll just point out that the program has an .interp section with a
string such as "/lib64/ld-linux-x86-64.so.2" identifying the dynamic linker
to use (which is also an ELF program, see man ld.so for more information).
This program is actually executed before our main as well since it is
responsible for loading the dynamic libraries.
Legacy (glibc < 2.34)
So far we've seen how a modern program is built and started, but it wasn't always exactly like this. It actually changed "recently", around 2018. We have to study how it was before because the crackme we're interested in is actually compiled in these pre-2018 conditions. The patterns we get don't match the modern construct we just observed.
If we look at how the Scrt1.o of glibc was before 2.34, we get the following:
0000000000000000 <_start>:
0: 31 ed xor ebp,ebp
2: 49 89 d1 mov r9,rdx
5: 5e pop rsi
6: 48 89 e2 mov rdx,rsp
9: 48 83 e4 f0 and rsp,0xfffffffffffffff0
d: 50 push rax
e: 54 push rsp
f: 4c 8b 05 00 00 00 00 mov r8,QWORD PTR [rip+0x0] # 16 <_start+0x16>
16: 48 8b 0d 00 00 00 00 mov rcx,QWORD PTR [rip+0x0] # 1d <_start+0x1d>
1d: 48 8b 3d 00 00 00 00 mov rdi,QWORD PTR [rip+0x0] # 24 <_start+0x24>
24: ff 15 00 00 00 00 call QWORD PTR [rip+0x0] # 2a <_start+0x2a>
2a: f4 hlt
It's pretty similar to what we've seen before but we can see more relocation
entries (see r8 and rcx registers). A grasp on the x86-64 calling
convention is going to be helpful here: a function is expected to read its
arguments in the following register order: rdi, rsi, rdx, rcx, r8,
r9 (assuming no floats). In the dump above we can actually see all these
registers being loaded before the call instruction, so they're very likely
preparing the arguments for that __libc_start_main call.
At this point, we need to know more about __libc_start_main actual prototype.
Looking on the web for it, we may land on such a page:

This is extremely outdated. It is actually a prototype from a long time
ago when the init function passed as argument didn't receive any parameter.
The prototype for __libc_start_main in glibc now looks like this (extracted,
tweaked and commented for clarity from glibc/csu/libc-start.c):
int __libc_start_main(
int (*main)(int, char **, char ** MAIN_AUXVEC_DECL), /* RDI */
int argc, /* RSI */
char **argv, /* RDX */
__typeof (main) init, /* RCX */
void (*fini)(void), /* R8 */
void (*rtld_fini)(void), /* R9 */
void *stack_end /* RSP (stack pointer) */
)
The init parameter now matches the prototype of the main. For those
interested in archaeology, this is true since 2003, which I
believe is around the Palaeolithic period.
Going back to our __libc_start_main() call at the entry point: there is now 2
extra arguments compared to the modern version: rcx (the init argument) and
r8 (the fini argument). These are respectively going to point to two
functions respectively called __libc_csu_init and __libc_csu_fini. In
Ghidra if the binary is not stripped we observe the following:
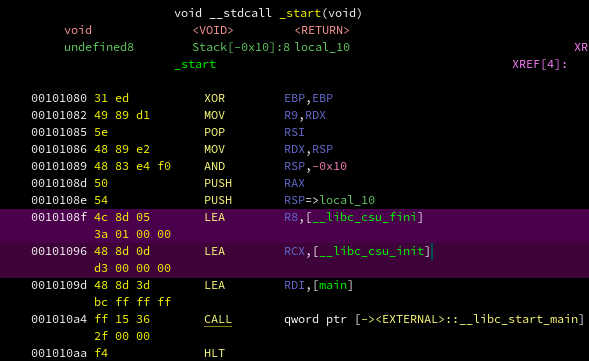
Now here is the trick: where do you think these functions are located? One may
expect to have them in the glibc, just like __libc_start_main, but that's not
the case. They are actually embedded within our ELF binary. The reason for this
is still unclear to me.
The mechanism of injecting that code inside the binary was also a mystery to
me: while the canonical crt1.o mechanism is followed by build toolchains
since forever, that object doesn't contain __libc_csu_init and
__libc_csu_fini. So where the hell do they even come from? Well, here is the
magic trick (thank you strace):
% file /lib/libc.so
/lib/libc.so: ASCII text
% cat /lib/libc.so
/* GNU ld script
Use the shared library, but some functions are only in
the static library, so try that secondarily. */
OUTPUT_FORMAT(elf64-x86-64)
GROUP ( /usr/lib/libc.so.6 /usr/lib/libc_nonshared.a AS_NEEDED ( /usr/lib/ld-linux-x86-64.so.2 ) )
That's right, just as deceptive as ld.so is a program, libc.so is a linker
script. We see it instructing the linker to use libc_nonshared.a, which is
another file distributed by the glibc, containing a bunch of functions, notably
__libc_csu_init and __libc_csu_fini. This means that thanks to this script,
this static non-shared archive containing yet another batch of weird init
routines, is dumped into every dynamically linked ELF executable. I'm still
having a hard time processing this.
Note
libc_nonshared.a still exists in the modern setup (as of 2.36 at least),
but it's much smaller and doesn't have those functions anymore.
So what are these functions doing? Well, they're responsible for calling the
pre and post-main functions, just like __libc_start_main is doing in its
modern setup. Here is what they looked like before getting removed in glibc
2.34 (extracted and simplified from glibc/csu/elf-init.c in 2.33):
void __libc_csu_init (int argc, char **argv, char **envp)
{
_init ();
const size_t size = __init_array_end - __init_array_start;
for (size_t i = 0; i < size; i++)
(*__init_array_start [i]) (argc, argv, envp);
}
void __libc_csu_fini (void)
{
_fini ();
}
Note
CSU likely stands for "C Start Up" or "Canonical Start Up".
The commit removing these functions is actually pretty damn interesting and we can learn a lot from it:
- it has security implications: the ROP gadgets referred to are basically snippets of instructions that are useful for exploitation, having them in the binary is a liability
__libc_start_main()kept its prototype for backward compatibility, soinitandfiniarguments are still there, just passed asNULL(look at the 2xorinstructions in the modernScrt1.oshared earlier)- the forward compatibility on the other hand is not possible: we can run an old executable on a modern system, but we cannot run a modern executable on an old system
With all that new knowledge we are now armed to decipher the startup mechanism of our crackme.
Within Ghidra
After analysis, the entry point of our crackme looks like this:
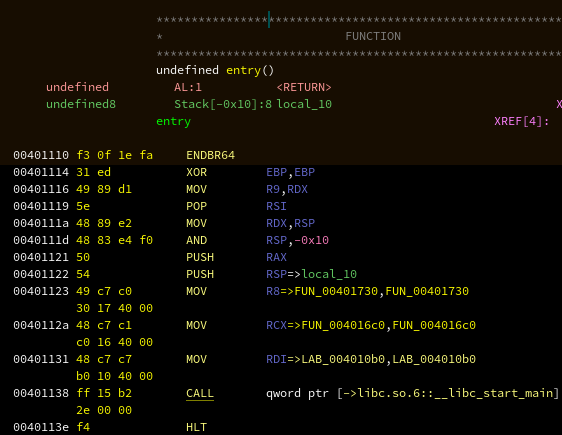
We recognize the _start pattern of our crt1.o. More specifically, we can
see that it's loading 2 pointers in rcx and r8, so we know we're in the
pattern pre-2018:
r8:FUN_00401730is__libc_csu_finircx:FUN_004016c0is__libc_csu_initrdi:LAB_004010b0ismain
If we want to find the custom inits, we have to follow __libc_csu_init, where
we can see it matching the snippet shared earlier, except __init_array_start
is named __DT_INIT_ARRAY but still located at the .init_array ELF section.
And in that table, we find again our init callbacks:
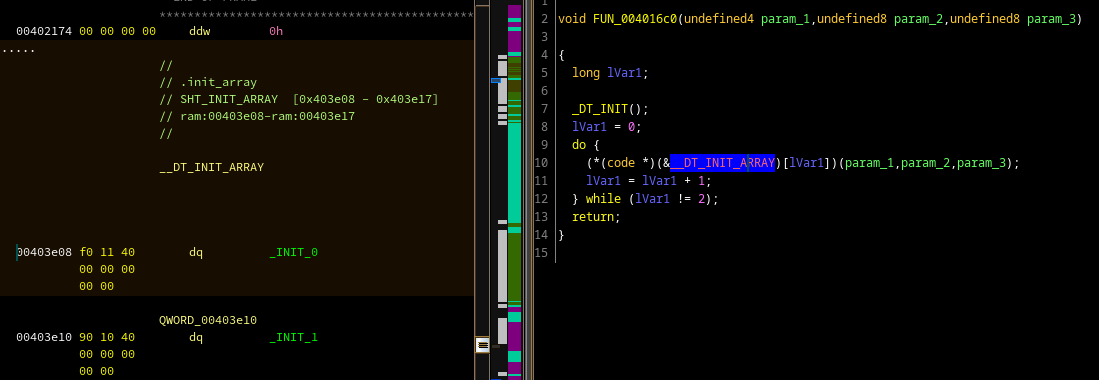
_INIT_0 corresponds to frame_dummy, and _INIT_1 is the first user
constructor. So just like ctor in sample C code, we are interested in what's
happening in _INIT_1, which is the function shown earlier calling signal.
Of course, someone familiar with this pattern will go straight into the
.init_array section, but with crackmes you never know if they're actually
going to follow the expected path, so it's a good thing to be familiar with the
complete execution path.
Going deeper, uncovering Ghidra bugs
We could stop our research on the init procedure here but I have to make a detour to talk about some unfortunate things in x86-64 and Ghidra (as of 10.1.5).
If we look at the decompiler view of the entry point, we see a weird prototype:
void entry(undefined8 param_1,undefined8 param_2,undefined8 param_3)
{
/* ... */
}
The thing is, when a program entry point is called, it's not supposed to have 3
arguments like that. According to glibc sysdeps/x86_64/start.S (which is the
source of crt1.o), here are the actual inputs for _start:
This is the canonical entry point, usually the first thing in the text
segment. The SVR4/i386 ABI (pages 3-31, 3-32) says that when the entry
point runs, most registers' values are unspecified, except for:
%rdx Contains a function pointer to be registered with `atexit'.
This is how the dynamic linker arranges to have DT_FINI
functions called for shared libraries that have been loaded
before this code runs.
%rsp The stack contains the arguments and environment:
0(%rsp) argc
LP_SIZE(%rsp) argv[0]
...
(LP_SIZE*argc)(%rsp) NULL
(LP_SIZE*(argc+1))(%rsp) envp[0]
...
Basically only the rdx register is expected to be set (along with the stack
and its register) which the program entry function usually forwards down to
__libc_start_main (as rtld_fini argument) which itself passes it down to
atexit. You will find similar information in the kernel in its ELF loader
code.
Do you remember the x86-64 calling convention from earlier? The function
arguments are passed in the following register order: rdi, rsi, rdx,
rcx, r8, r9. But like we just saw the entry point code of the program is
expected to only read rdx (equivalent to the 3rd argument in the calling
convention), while rdi and rsi content is undefined. Since the program
entry point is usually respecting that (reading rdx to get rtld_fini),
Ghidra infers that the 1st and 2nd argument must also exist, and get confused
when rdi and rsi are actually overridden to setup the call to
__libc_start_main instead.
Now one may ask, why even use rdx in the 1st place if it conflicts with the
calling convention? Well, on 32-bit it uses edx, which makes a little more
sense to use since it doesn't overlap with the calling convention: all the
function arguments are expected to be on the stack on 32-bit. And during the
move to 64-bit they unfortunately just extended edx into rdx.
While not immediately problematic, I still don't know why they decided to use
edx on 32-bit in the kernel instead of the stack though; apparently this is
described in "SVR4/i386 ABI (pages 3-31, 3-32)" but I couldn't find much
information about it.
Anyway, all of this to say that until the NSA fixes the bug, I'd
recommend to override the _start prototype: void entry(undefined8 param_1,undefined8 param_2,undefined8 param_3) should be void _start(void),
and you should expect the code to read the rdx register.
Remaining bits of the algorithm
Alright, so we're back to our previous flow. Assuming the division raised a
floating point error, we're following the callback forwarded to signal(), and
we end up at another location, which after various renames and retyping in
Ghidra decompiler looks like this:
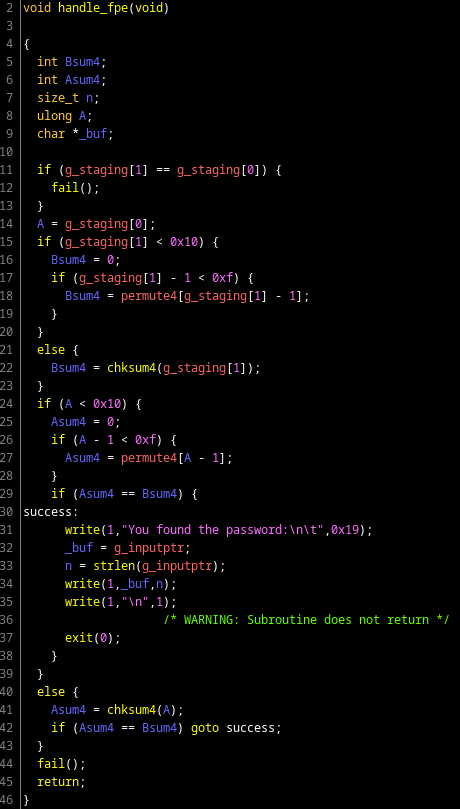
I'll spare you the details since it's an overly complex implementation of a very simple routine:
- Read the 2 halves of registers stored earlier (remember half of
lane2andlane3were stored for later use, here is where we read them back) - Check that those are different
- For each halves, make the sum of each element of the data by slicing it in nibbles (4-bits), with each nibble value being permuted using a simple table
- Check that the checksums are the same
And that's pretty much it.
Now we roughly know how the 64 bytes of input are read and checked. There is
one thing we need to study more though: the div instruction.
Oddity #1: the division
We need to understand how the div instruction works since it's the trigger to
our success path. Here is what the relevant Intel documentation says about it:
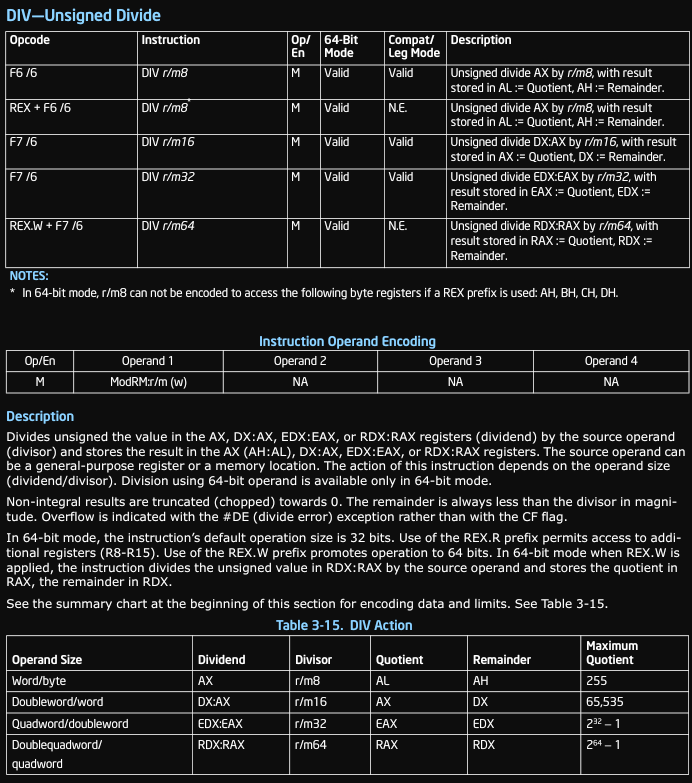
In English this means that if we have div rbx, then the registers rdx and
rax are combined together to form a single 128-bit value, which is then
divided by rbx.
As a reminder, the chunk doing the division looks like this:
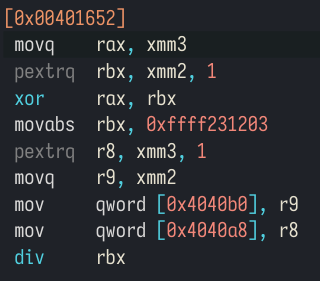
- Our divider is
rbx, a large hardcoded number:0xffff231203(meaning the exception cannot be a division by zero, but could be an overflow) raxcontains the lower part of thexmm3register (the 4th lane) xored with the higher part of thexmm2register (the 3rd lane)rdxcontains… wait, what does it contain? We don't know.
Looking through the code, rdx value looks pretty much undefined. If it's big
enough, the result of the division will luckily not fit in a 64-bit register
and will overflow, causing the floating point exception. Under "normal"
conditions it seems to happen, but if run through let's say valgrind, rdx
will be initialized to something else and the overflow won't be triggered.
This is actually a bug, an undefined behavior in the crackme. That's too bad because the original idea was pretty good. But it also means we won't have to think much about whatever data we put into that part of the input.
Oddity #0
One last oddity before we're ready to write a keygen: the Oddity #0 is a
write of a 128-bit register at an address where only 64 bits are available,
located at the end of the .bss section. For some reason the code still works
so I'm assuming we are lucky thanks to some padding in the memory map…
The issue can actually easily be noticed because it drives the decompiler nuts in that area:

If you patch the instruction from xmmword ptr [0x004040b0],XMM1 to xmmword ptr [0x004040a8],XMM1, you'll observe everything going back to normal in the
decompiler view.
I later became aware about the code source of the crackme on Github, so I could see why the mistake happened in the first place. I reported the issue if you want more information on that topic.
Writing the keygen
Onto the final step: writing a keygen.
To summarize all the conditions that need to be met:
- Input length must be 64-bytes long
- Xor'ing each character of the 1st lane with each other (after encoding with the xor key) must be 0
- The sum of all the characters of the 2nd lane must be equal to:
(lane0[11] ^ xor_key[11]) × 136 + 314 - The first half of the 3rd lane and the 2nd half of the 4th lane must be different
- The sum of the permuted nibbles of the first half of the 3rd lane and the 2nd half of the 4th lane must be equal
- The 2nd half of the 3rd lane and the 1st half of the 1st lane don't really matter
I don't think solving this part is the most interesting, particularly for a reader, but I described the strategy I followed in the keygen code, so I'll just share it as is:
# Range of allowed characters in the input; we'll use the xor key as part of
# the password so we're kind of constraint to its range
xor_key = bytes.fromhex("64 47 34 36 72 73 6b 6a 38 2d 34 35 37 28 7e 3a")
ord_min, ord_max = min(xor_key), max(xor_key)
def xor0(data: str) -> int:
"""Encode the data using the xor key"""
assert len(data) == len(xor_key) == 16
r = 0
for c, x in zip(data, xor_key):
r ^= ord(c) ^ x
return r
def get_lane0(k11: str) -> str:
"""
Compute lane0 of the input
We have the following constraints on lane0:
- the character at position 11 must be k11
- xoring all characters must give 0
- input characters must be within accepted range (self-imposed)
Strategy:
- start with the xor key itself because the xor reduce will give our
perfect zero score
- replace the 11th char with our k11 and figure out which bits get off
because of it
- go through each character to see if we can flip the off bits
"""
lane0 = "".join(map(chr, xor_key))
lane0 = lane0[:11] + k11 + lane0[12:]
off = xor0(lane0)
off_bits = [(1 << i) for i in range(8) if off & (1 << i)]
fixed_lane0 = lane0
for i, c in enumerate(lane0):
if i == 11:
continue
remains = []
for bit in list(off_bits):
o = ord(c) ^ bit
if ord_min <= o <= ord_max:
c = chr(o)
else:
remains.append(bit)
fixed_lane0 = fixed_lane0[:i] + c + fixed_lane0[i + 1 :]
off_bits = remains
if not off_bits:
break
assert not off_bits
off = xor0(fixed_lane0)
assert xor0(fixed_lane0) == 0
return fixed_lane0
def get_lane1(t: int) -> str:
# First estimate by taking the average
avg_ord = t // 16
assert ord_min <= avg_ord <= ord_max
lane1 = [avg_ord] * 16
# Adjust with off by ones to reach target if necessary
off = sum(lane1) - t
if off:
sgn = [-1, 1][off < 0]
for i in range(abs(off)):
lane1[i] += sgn
assert sum(lane1) == t
return "".join(map(chr, lane1))
def get_divdata():
# The div data doesn't really matter, so we just use some slashes to carry
# the division meaning
d0 = d1 = "/" * 8
return d0, d1
def chksum4(data: str) -> int:
"""nibble (4-bit) checksum"""
permutes4 = [0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4]
return sum(permutes4[ord(c) >> 4] << 4 | permutes4[ord(c) & 0xF] for c in data)
def get_chksums4():
# We need the value to be different but the checksum to be the same, so we
# simply interleave 2 working characters differently
c0 = (chr(ord_min) + chr(ord_max)) * 4
c1 = (chr(ord_max) + chr(ord_min)) * 4
assert c0 != c1
assert chksum4(c0) == chksum4(c1)
return c0, c1
def get_passwords():
# The user input key is composed of 4x16B, which will be referred to as 4
# lanes: lane[0..3]. The character at lane0[11] defines what is going to be the
# target T that S=sum(lane1) will need to reach. Here we compute all potential
# T value that can be obtained within our range of characters.
x11 = xor_key[11]
allowed_ords = range(ord_min, ord_max + 1)
all_t = {136 * (o ^ x11) + 314: o for o in allowed_ords}
# Compute the extreme sums our input lane1 can reach and filter out T values
# that land outside these boundaries
min_t, max_t = ord_min * 16, ord_max * 16
possible_t = {t: chr(k11) for t, k11 in all_t.items() if min_t <= t <= max_t}
for t, k11 in possible_t.items():
lane0 = get_lane0(k11)
lane1 = get_lane1(t)
d0, d1 = get_divdata()
c0, c1 = get_chksums4()
lane2 = c0 + d0
lane3 = d1 + c1
password = lane0 + lane1 + lane2 + lane3
assert len(password) == 16 * 4
yield password
for password in get_passwords():
print(password)
It executes instantly and gives the following keys (it's not exhaustive to all possibilities):
% python 615888be33c5d4329c344f66_cm001.py
aG46rskj8-407(~:??>>>>>>>>>>>>>>(~(~(~(~////////////////~(~(~(~(
`G46rskj8-417(~:6666666666555555(~(~(~(~////////////////~(~(~(~(
cG46rskj8-427(~:PPOOOOOOOOOOOOOO(~(~(~(~////////////////~(~(~(~(
bG46rskj8-437(~:GGGGGGGGGGFFFFFF(~(~(~(~////////////////~(~(~(~(
gG46rskj8-467(~:..--------------(~(~(~(~////////////////~(~(~(~(
hG46rskj8-497(~:zzzzzzzzzzyyyyyy(~(~(~(~////////////////~(~(~(~(
mG46rskj8-4<7(~:aa``````````````(~(~(~(~////////////////~(~(~(~(
lG46rskj8-4=7(~:XXXXXXXXXXWWWWWW(~(~(~(~////////////////~(~(~(~(
oG46rskj8-4>7(~:rrqqqqqqqqqqqqqq(~(~(~(~////////////////~(~(~(~(
nG46rskj8-4?7(~:iiiiiiiiiihhhhhh(~(~(~(~////////////////~(~(~(~(
All of these seem to be working keys. We can visually see how each segment corresponds to a specific part of the algorithm. The keys are ugly, but at least they're printable.
The most tricky part for me was to anticipate the range of guaranteed keys, due
to the dependency between lane0 and lane1, the rest was relatively simple.
Conclusion
I didn't expect such a ride to be honest. There were just so many incentives to dig down the rabbit hole of various intricacies. The bugs in the crackme caused me a lot of confusion, but I don't think they're even close to the obfuscated level of the glibc and its messy history of deceptive patterns.