This is the end of the holidays in which I spent a long time building a backup infrastructure like a responsible adult. The villain of the following story is the junk MIPS machine which held hostage most of my important data (about 1TB). Its evil plan was to build up a corrupted backup snapshot for a whole week and have me deal with it. Various options were available to me, but I decided to use the scalpel and manually strike at the core.

The plot
Long story short, this is the plot in technical terms:
- Restic is a popular backup system in which every time you call a
backupcommand, it will create a new snapshot of the pointed data, encrypt it, and push it over a dedicated repository - The MIPS machine holding my data ran one
restic backupcommand on a remote (and more reliable) machine. This process took about a week because the MIPS CPU is anemic. - The snapshot seemed to be fine (
restic checkraised no error) - Trying to
restic copythat repository to another location was unfortunately causing an error at around 25%
This was the error:
LoadBlob(9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27) returned error
blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27 returned invalid hash
The beginning of an adventure
Before starting, we need some serious information gathering, and a clear understanding of how things work. The restic references page is a goldmine for that. Here are a few interesting bits in order to understand the rest of the story:
- In a restic repository, the data is stored into packs. A pack is simply one
file located in the
datadirectory of a repository. - Each pack contains a chain of independent blobs and a header at the end
- A blob is a chunk of encrypted data, encapsulated with a few crypto information
With that much information we can already start investigating. We know one of the blob (a chunk of data in a given pack file) has an integrity error according to our error message. We need to identify where it is located, and to which data (file) it actually corresponds:
% restic find --show-pack-id --blob 9f02880a
repository 390a6747 opened successfully, password is correct
Found blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27
... in file /saving/private/ryan.mp3
(tree f73fb24fa4f8c0885452a51c3d97912efe44fd8f72907eda446bcada4463a309)
... in snapshot cd60b511 (2021-08-29 00:57:08)
Object belongs to pack fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73
... Pack fdd48b5c: <Blob (data) 9f02880a, offset 3120083, length 3401765>
We indeed find a data/fd/fdd48b5c... file on the remote repository, which we
can grab right away in order to work with it later down the line.
After building restic in debug mode (go build -tags debug ./cmd/restic), we
can also dump the pack using debug examine --extract-pack. Here is what we
get:
% ls dump
-rw-r--r-- 1 ux ux 606141 Sep 5 13:42 correct-bd30e59fb99f30794bb5c4c8d3460eb22627433a6f0a7a07087a4e56b9f2276c.bin
-rw-r--r-- 1 ux ux 1738374 Sep 5 13:42 correct-becb3f4e8308b26ff66d2ba5cf85c15f73daf432c3c61d9f61c55f212aa26b7e.bin
-rw-r--r-- 1 ux ux 775472 Sep 5 13:42 correct-f0def1ccba1c6efe30b4dc14b67d68db1a6b81e44e7d4cba18a1330477abe877.bin
-rw-r--r-- 1 ux ux 3401733 Sep 5 13:42 wrong-hash-f99b85dbc25b54e1fa16fe75f33118e4a347644f62602913c41907878e902f47.bin
Note
These blobs are in a decrypted state, but the encrypted data would be the same size since restic is using AES256 CTR.
From the dump log we also get the layout (the order in which the blobs are packed):
data blob becb3f4e8308b26ff66d2ba5cf85c15f73daf432c3c61d9f61c55f212aa26b7e, offset 0 , raw length 1738406
data blob f0def1ccba1c6efe30b4dc14b67d68db1a6b81e44e7d4cba18a1330477abe877, offset 1738406, raw length 775504
data blob bd30e59fb99f30794bb5c4c8d3460eb22627433a6f0a7a07087a4e56b9f2276c, offset 2513910, raw length 606173
data blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27, offset 3120083, raw length 3401765
We also notice this information:
loading blob 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27 at 3120083 (length 3401765)
successfully decrypted blob (length 3401733), hash is f99b85dbc25b54e1fa16fe75f33118e4a347644f62602913c41907878e902f47, ID does not match, wanted 9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27
decrypt of blob f99b85dbc25b54e1fa16fe75f33118e4a347644f62602913c41907878e902f47 stored at wrong-hash-f99b85dbc25b54e1fa16fe75f33118e4a347644f62602913c41907878e902f47.bin
In particular: 9f02880a is the expected hash, but we do get f99b85db
instead.
Since we have a mismatch between the hash and the data, we need to figure out
which one is wrong. Fortunately for me, I have archaic backups everywhere, so I
was able to grab the original file for comparison. This file will be called
ryan.mp3 (as in "/saving/private/ryan.mp3") for the rest of the story.
We notice that ryan.mp3 is bigger than the pack file (and so even bigger than
the blob it corresponds to):
-rw------- 1 ux ux 6522032 Sep 5 14:12 fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73
-rw-r--r-- 1 ux ux 10418993 Sep 5 13:34 ryan.mp3
Before truncating our reference (ryan.mp3), we can check the impact of the
diff with the corresponding blob (wrong-hash-f99b85db....bin):
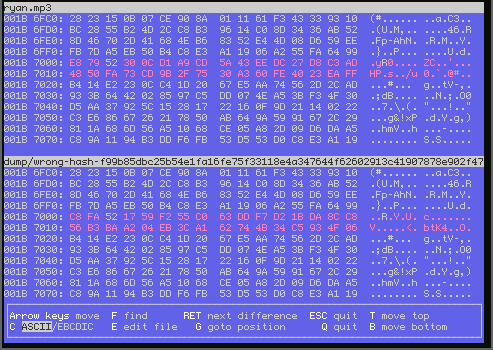
So the data blob (and not the hash) is wrong: 32 bytes are off. This could be because of a hardware memory issue, typically a random bitflip during encryption as suggested in the help-wanted forum post I made (who needs ECC memory heh?).
Data reconstruction
The previous diff shows that the wrong-hash blob starts at the beginning of
the file. We can truncate our ref to obtain the desired correct blob:
% dd if=ryan.mp3 of=ryan-cut.mp3 bs=3401733 count=1
1+0 records in
1+0 records out
3401733 bytes (3.4 MB, 3.2 MiB) copied, 0.00986717 s, 345 MB/s
A checksum shows that our blob now has the expected hash:
% sha256sum ryan-cut.mp3
9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27 ryan-cut.mp3
This is perfect: it confirms that the metadata are correct but the encrypted data blob isn't. We add our newly corrected data blob to the dump directory (for later use):
% cp ryan-cut.mp3 dump/correct-$(sha256sum ryan-cut.mp3|head -c64).bin
Encryption now. The documentation says:
Apart from the files stored within the keys directory, all files are encrypted with AES-256 in counter mode (CTR).
The documentation also indicates that the layout of blobs (and most of the objects) follows this simple structure:
| Block | Size |
|---|---|
| IV | 16B |
| Ciphertext (encrypted data) | variable |
| MAC info | 16 |
For the pack file, it is:
| Block | Size |
|---|---|
| Blob #0 | variable |
| Blob #1 | variable |
| Blob #2 | variable |
| ... | |
| Blob #N | variable |
| Header | Length |
| Length | 4B (little-endian) |
Our pack file contains a header length of 0x000000B4 (180). If we sum all our
dumped blob sizes with it (accounting IV and Mac) plus the 4B of the header
length, we have:
>>> blob_sizes = [606141, 1738374, 775472, 3401733]
>>> s = sum(blob_sizes)
>>> s += len(blob_sizes) * (16 + 16)
>>> s += 180
>>> s += 4
>>> s
This exactly matches the size of our pack file, so we're on the right track.
Now to confirm that we have a proper understanding of the layout, we could re-encrypt every blob from the dump directory, and compare them to what is inside the raw packfile:
#!/bin/bash
set -uex # -e mandatory to make sure `cmp` breaks the execution in case of error
# Fetch the master encryption key as a hex string using the restic API
blob_key=$(restic cat masterkey | jq -r .encrypt | base64 -d | xxd -p -c32)
broken_packfile=fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73
# Ordered list of blobs present in the broken packfile
blobs=$(cat << END
dump/correct-becb3f4e8308b26ff66d2ba5cf85c15f73daf432c3c61d9f61c55f212aa26b7e.bin
dump/correct-f0def1ccba1c6efe30b4dc14b67d68db1a6b81e44e7d4cba18a1330477abe877.bin
dump/correct-bd30e59fb99f30794bb5c4c8d3460eb22627433a6f0a7a07087a4e56b9f2276c.bin
dump/wrong-hash-f99b85dbc25b54e1fa16fe75f33118e4a347644f62602913c41907878e902f47.bin
END
)
rm -f dump/*.enc dump/*.ref
iv_size=16
mac_size=16
offset=0
for blob in $blobs; do
# Extract the blob IV
blob_iv=$(cat $broken_packfile | xxd -seek $offset -p -l16)
# Encrypt blob with AES-256 CTR using the blob IV and the master key
openssl aes-256-ctr -e -in $blob -out $blob.enc -iv $blob_iv -K $blob_key
blob_off=$(($offset+$iv_size))
blob_cyphertext_size=$(stat -c '%s' $blob)
# Extract the encrypted blob from the packfile to compare with our own
dd if=$broken_packfile of=$blob.ref ibs=1 count=$blob_cyphertext_size skip=$blob_off 2>/dev/null
# Compare what we encrypted with what's in the packfile
cmp $blob.enc $blob.ref
length=$(($iv_size+$blob_cyphertext_size+$mac_size))
offset=$(($offset+$length))
done
Running this doesn't fail, which means we were able to re-encode every blob
exactly the same as they appear within that packfile. So now, how about we
replace the wrong-hash-f99b85db....bin file with our carefully crafted
correct-9f02880a....bin file and re-encapsulate a new packfile?
Let's adjust our script:
#!/bin/bash
set -uex
# Fetch the master encryption key as a hex string using the restic API
blob_key=$(restic cat masterkey | jq -r .encrypt | base64 -d | xxd -p -c32)
broken_packfile=fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73
fixed_packfile=${broken_packfile}.fixed
# Ordered list of blobs to repack into a new pack file
blobs=$(cat << END
dump/correct-becb3f4e8308b26ff66d2ba5cf85c15f73daf432c3c61d9f61c55f212aa26b7e.bin
dump/correct-f0def1ccba1c6efe30b4dc14b67d68db1a6b81e44e7d4cba18a1330477abe877.bin
dump/correct-bd30e59fb99f30794bb5c4c8d3460eb22627433a6f0a7a07087a4e56b9f2276c.bin
dump/correct-9f02880a10db561af97a6e1d69d3cc85936951fc6eb020c638f5422ea2268c27.bin
END
)
# Start with the broken pack file as base (so that we preserve all existing
# IV, MAC, headers)
cp $broken_packfile $fixed_packfile
rm -f dump/*.enc
iv_size=16
mac_size=16
offset=0
for blob in $blobs; do
# Extract the blob IV
blob_iv=$(cat $broken_packfile | xxd -seek $offset -p -l16)
# Encrypt blob with AES-256 CTR using the blob IV and the master key
openssl aes-256-ctr -e -in $blob -out $blob.enc -iv $blob_iv -K $blob_key
blob_off=$(($offset+$iv_size))
blob_cyphertext_size=$(stat -c '%s' $blob)
# Insert the newly encoded blob into our pack file at its correct location
dd if=$blob.enc of=$fixed_packfile bs=1 count=$blob_cyphertext_size seek=$blob_off conv=notrunc
length=$(($iv_size+$blob_cyphertext_size+$mac_size))
offset=$(($offset+$length))
done
We are now in possession of a packfile with the data corrected, where all the blobs match their respective checksum. Is this a win?
Alas, replacing the data file with our new one brings this new error when
trying a restic cat blob 9f02880a: "ciphertext verification failed". Sad.
This is because while the checksum is now correct, the MAC signature (the 16B at the end of the blob) is now wrong, so we need to correct it.
After trying to recompute it manually using openssl for an hour, I figured a simpler way to achieve that would be to patch restic to leak the expected mac:
diff --git a/internal/crypto/crypto.go b/internal/crypto/crypto.go
index 56ee61db..f2b48a66 100644
--- a/internal/crypto/crypto.go
+++ b/internal/crypto/crypto.go
@@ -121,7 +121,14 @@ func poly1305Verify(msg []byte, nonce []byte, key *MACKey, mac []byte) bool {
var m [16]byte
copy(m[:], mac)
- return poly1305.Verify(&m, msg, &k)
+ ret := poly1305.Verify(&m, msg, &k)
+ if ! ret {
+ var tmp [16]byte
+ poly1305.Sum(&tmp, msg, &k)
+ fmt.Println("expected", tmp, "got", m)
+ }
+
+ return ret
}
// NewRandomKey returns new encryption and message authentication keys.
Running a restic cat blob again still fails but it also prints the key on
stdout, which we can store in a fixed.mac file:
>>> s = '60 8 175 15 140 206 212 132 102 59 123 192 61 19 34 36'
>>> with open('fixed.mac', 'wb') as f:
... f.write(b''.join(int(x).to_bytes(1, 'little') for x in s.split()))
...
16
We also need to find where exactly the mac is located, so we add this to our repacking script:
mac_offset=$(($offset+$iv_size+$blob_cyphertext_size))
blob_mac=$(cat $broken_packfile | xxd -seek $mac_offset -p -l16)
echo "mac_offset:$mac_offset blob_mac:$blob_mac"
After double checking that the blob_mac: matches the restic "got" log, we can
patch it in our pack file using the mac_offset as seek argument to dd:
% dd if=fixed.mac of=fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73.fixed bs=1 seek=6521832 count=16 conv=notrunc
And that's it, we can now replace data/fd/fdd48b5c... with our new fixed file
and profit, because this time you're goddamn right it works.
EDIT 2021/09/12
It works, we can read the file properly, checksum is fine, but restic will
still report index errors when running a check --read-data. One thing we
forgot is that the pack file checksum also changes:
% sha256sum fdd48b5c*
fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73 fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73
fdd48b5c364ad5004324312e10c78bc0101095de141022c8775d14485fd77e73.fixed 81b4816c341d7f60f10e6a554d6b7053d1216d16dd688437c728479490e4eff6
This means we must add data/81/81b4816c and remove data/fd/fdd48b5c...,
then run restic rebuild-index. This gets rid of the remaining issue. Thanks
to Michael Eischer from the restic forum for the hints.
Closing words
One could argue that I could have relied on higher level tools provided by restic and simply removed the packfile, re-indexed the repo and made a new snapshot (or something along these lines). This would have been more generic, simpler and probably more reliable. But it also has its drawbacks. First of all, it implies that you trust the tools for repairing a repository, which are probably based on various heuristics, likely less tested as those are pretty rare and specific scenarios.
Also, and this was important to me, I wanted to understand how restic worked because I trust this system with the most precious data in my life. This issue was actually a very good opportunity to get comfortable with its internals, and it also re-enforced the confidence I have in the tool and in myself to face such issue in the future.
And finally, heck, it was fun.
Oh, and for the curious, the MIPS machine is a GnuBee. I'm not going to badmouth it because it served its purpose and it's an awesome initiative (in particular because it allowed me to use my large stack of 2.5" hard drives in a very compact form factor), but on the other hand it's going to be hammered soon because I don't negotiate with terrorists.