A few months ago, I finished school and quit my job around the same time. After waiting several years for this, I went to Japan with a friend. We traveled around the country for about one month, wondering where to sleep the next day (a privilege we could afford because it wasn't the high season).

Anyway, despite the fact that this country and the people are awesome in many ways, it was sometimes extremely frustrating not to be able to speak with locals. Except in Tokyo, most of them are worse than French people in English, so this is a problem. Also, outside the big cities and touristic areas, if you can't read anything you're pretty doomed.
It is impossible to understand properly a country without digging into the language, so I decided to learn it, and go back there as soon as I can, to experience it differently.
But I'm still a nerd...
...and obviously, I'm lazy. Additionally, I have a fairly bad memory. Unluckily, Japanese is said to be one of the most difficult language to learn, notably because of the amount of data you have to swallow.
Whatever method you decide to follow to learn it, you will have to know thousands of Kanji. You can't avoid it, it's the basis.
So I've tried to come up with an easier way of learning them than just repeating them one by one a hundred times. The first idea is that a lot these Kanji are composed of some others, so you can make links between them. The second idea is that a Kanji is - often - associated with a specific meaning (it's not like the Hiragana and Katakana which are just "pronunciation symbols"); this means that you can most of time associate it with a little story to help memorization. This is nothing new, you can often hear about such memorization "trick" in TED talks.
Using these two centrals ideas, I took the list of the most important Kanji, and one by one I came up with a small story, added the different pronunciations, and linked them to the other Kanji where they come from. Of course, I got bored pretty quickly doing it manually so I automatized the graph construction, and only maintained a growing list of Kanji to learn, associated with "the little story". Basically, something like this:
# ...
'町': '田 and more, a town is near',
'森': 'a lot of 木 make a forest',
'正': None,
'水': None,
'火': None,
'玉': 'easy to lose it under a table, but can be precious',
'王': 'the king is like the 生 without its impurity; the clean steps also suggest the domination',
'石': "this kanji is annoying as it looks like 右, lets walk on it or throw it away like a rock (it won't hurt since it's flat on the top)",
'竹': None,
'糸': 'a node obviously, or just a thread mess',
'貝': 'pleasant for the 目, and kawaii with its little legs (ハ)',
'車': 'symmetric and frightening to face, this is a man-made invention',
'金': 'a kind of wealthy house representing richness, opulence',
# ...
Note that these texts are very personal (in the sense they will work the best with me). If you plan to do the same, I'd recommend to make up your own stories. Also, I haven't filled all of them for various reasons; Kanji too obvious, links are explicit enough, lack of imagination, just waiting for more information on the related Kanji, don't have a meaning, ...
The only straightforward toolkit I know for constructing graph is Graphviz, so this is my starting point. Using free dictionaries from the WWWJDIC project, I ended up with something like this for the first 80 Kanji (low res):

This generated map is currently good enough for me; I browse the high resolution of this with my image viewer, and I can easily learn and make relationships between the Kanji.
Failures
Graphviz
So many troubles... The only tool giving a decent output is fdp. All the
others (dot, neato, circo, ...) fail one way or another. In the best case
it's unreadable, in the worse it crashes. And I'm still not satisfied with the
current output.
Additional information
It is important to know that the most difficult thing about the Kanji isn't actually their meaning. It's the pronunciations. Kanjis have multiple pronunciations of a single Kanji (from 2 to dozens). And those pronunciations are very often shared between them (you can have hundreds different Kanji - so with a different meaning - with a common pronunciation). I've tried to map this information, and it looks like this:
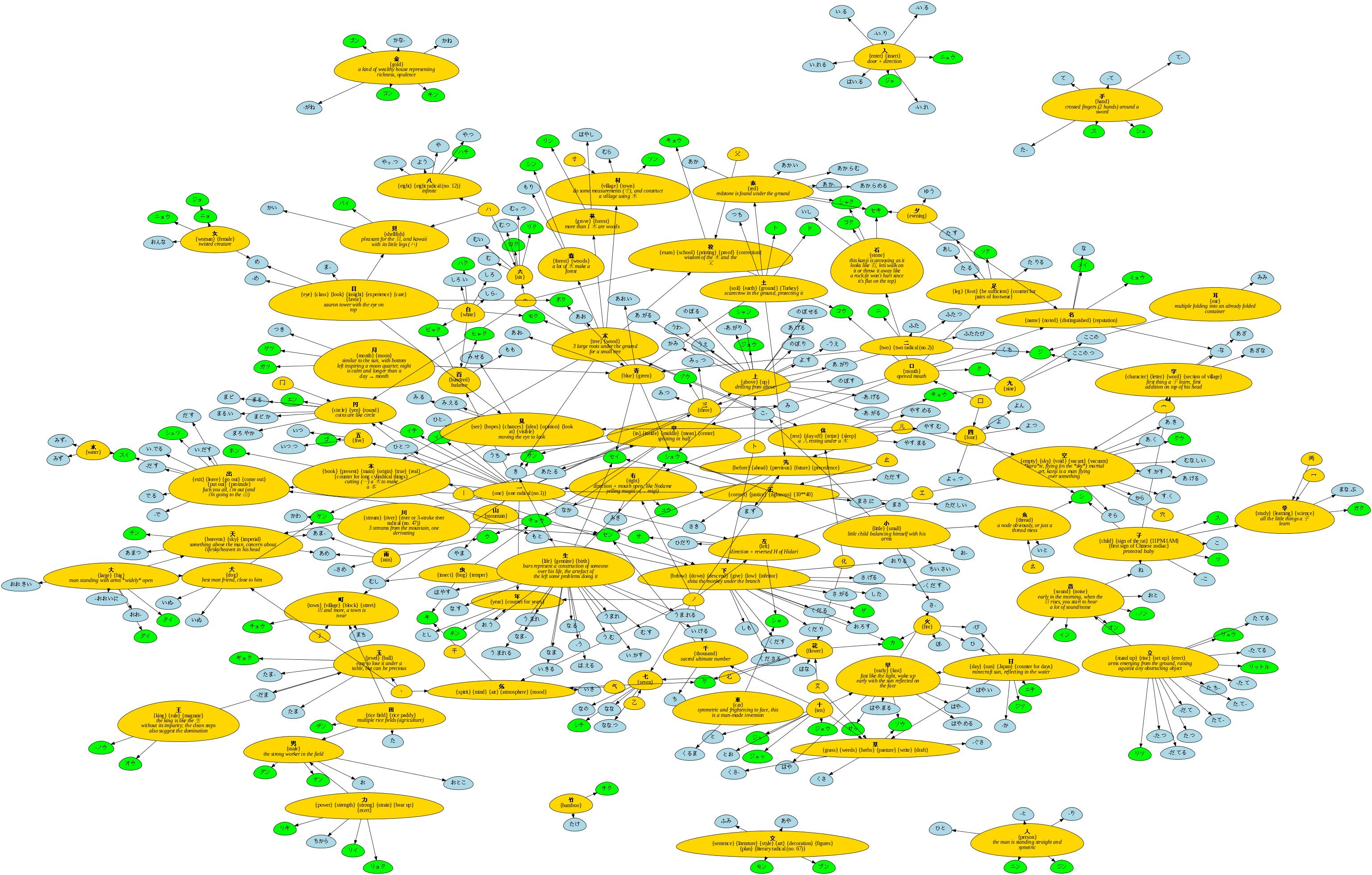
It's pretty, but it's unreadable. Remember, this is 80 Kanjis. The final graph is supposed to contain around 2000 (or up to 7000 in an ideal world). The final goal is learning them one by one by observing their relationships, not especially have an overview of the Japanese language in its whole.
Note: different colors are used for the Hiragana (used to write the Kun reading) and Katakana (used to write the On reading), even though they sound exactly the same.
A few requests to the community
Ideally it would be great to be able to browse such graph in 3D, or at least a
better 2D representation if possible. If such tool exists, ideally supporting a
simple and straightforward syntax such as Graphviz, please share.
Also, an interactive application where you can basically observe the construction of the graph would be great too. Typically I want to press a key and see the next graph increment with the new added Kanji. It is possible to do that with my scripts (you just need to generate all the pictures and play with an image viewer). That's just not handy, and very slow to re-generate everything when doing an edit of, for instance, one of the Kanji text. I believe a tool like this could really help a lot.
I'm going to reach the limit of Graphviz (and the use of pictures) pretty
soon. If you have experienced such problem, I'm extremely interested.
Scripts
It's time for me to stop fooling around with this stuff and actually do my learning task. So if you want to play with this, following are the current state of the ugly/hack/scripts I used.
download_dic.sh to download the Kanji "databases":
#!/bin/sh
get_extract_convert() {
echo " :: $1"
[ -f $1 ] && return
wget -c "http://ftp.monash.edu.au/pub/nihongo/${1}.gz"
gunzip ${1}.gz
iconv -f euc-jp -t utf-8 ${1} > ${1}.utf8
}
get_extract_convert kanjidic
get_extract_convert kradfile
And the main kanji.py script:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
kanji_to_learn = {
'一': None,
'二': None,
'三': None,
'四': None,
'五': None,
'六': None,
'七': None,
'八': 'infinite',
'九': None,
'十': None,
'百': 'balance',
'千': 'sacred ultimate number',
'上': 'drilling from above',
'下': 'shita the monkey under the branch',
'左': 'direction + reversed H of Hidari',
'右': 'direction + mouth open, like Nodame yelling mugiii~ (→ migi)',
'中': 'splitting in half',
'大': 'man standing with arms *widely* open',
'小': 'little child balancing himself with his arms',
'月': 'similar to the sun, with bottom left inspiring a moon quarter, night is calm and longer than a day → month',
'日': 'minecraft sun, reflecting in the water',
'年': None,
'早': 'fast like the light, wake up early with the sun reflected on the face',
'木': '3 large roots under the ground for a small tree',
'林': 'more than 1 木 are woods',
'山': None,
'川': '3 streams from the mountain, one derivating',
'土': 'scarecrow in the ground, protecting it',
'空': '*kara*te, flying (in the *sky*) martial art, kanji is a man flying over something',
'田': 'multiple rice fields (agriculture)',
'天': 'something above the man, concern about life/sky/heaven in his head',
'生': 'bars represent a construction of someone over his life, the artefact of the left some problems doing it',
'花': None,
'草': None,
'虫': None,
'犬': 'best man friend, close to him',
'人': 'the man is standing straight and symetric',
'名': None,
'女': 'twisted creature',
'男': 'the strong worker in the field',
'子': 'protected baby',
'目': 'sauron tower with the eye on top',
'耳': 'multiple folding into an already folded container',
'口': 'opened mouth',
'手': 'crossed fingers (2 hands) around a sword',
'足': None,
'見': 'moving the eye to look',
'音': 'early in the morning, when the 日 rises, you start to hear a lot of sound/noise',
'力': None,
'気': None,
'円': 'coins are like circle',
'入': 'door + direction',
'出': "fuck you all, i'm out (and i'm going to the 山)",
'立': 'arms emerging from the ground, raising against any obstructing object',
'休': 'a 人 resting under a 木',
'先': None,
'夕': None,
'本': 'cutting (一) a 木 to make a 本',
'文': None,
'字': 'first thing a 子 learn, first addition on top of his head',
'学': 'all the little things a 子 learn',
'校': 'wisdom of the 木 and the 父',
'村': 'do some measurements (寸), and construct a village using 木',
'町': '田 and more, a town is near',
'森': 'a lot of 木 make a forest',
'正': None,
'水': None,
'火': None,
'玉': 'easy to lose it under a table, but can be precious',
'王': 'the king is like the 生 without its impurity; the clean steps also suggest the domination',
'石': "this kanji is annoying as it looks like 右, lets walk on it or throw it away like a rock (it won't hurt since it's flat on the top)",
'竹': None,
'糸': 'a node obviously, or just a thread mess',
'貝': 'pleasant for the 目, and kawaii with its little legs (ハ)',
'車': 'symmetric and frightening to face, this is a man-made invention',
'金': 'a kind of wealthy house representing richness, opulence',
'雨': None,
'赤': 'redstone is found under the ground',
'青': None,
'白': None,
}
hiragana = [
'あ','い','う','え','お',
'か','き','く','け','こ',
'が','ぎ','ぐ','げ','ご',
'さ','し','す','せ','そ',
'ざ','じ','ず','ぜ','ぞ',
'た','ち','つ','て','と',
'だ','ぢ','づ','で','ど',
'な','に','ぬ','ね','の',
'は','ひ','ふ','へ','ほ',
'ば','び','ぶ','べ','ぼ',
'ま','み','む','め','も',
'ぱ','ぴ','ぷ','ぺ','ぽ',
'や', 'ゆ', 'よ',
'ら','り','る','れ','ろ',
'わ','ゐ', 'ゑ','を',
'ん'
]
katakana = [
'ア','イ','ウ','エ','オ',
'カ','キ','ク','ケ','コ',
'ガ','ギ','グ','ゲ','ゴ',
'サ','シ','ス','セ','ソ',
'ザ','ジ','ズ','ゼ','ゾ',
'タ','チ','ツ','テ','ト',
'ダ','ヂ','ヅ','デ','ド',
'ナ','ニ','ヌ','ネ','ノ',
'ハ','ヒ','フ','ヘ','ホ',
'バ','ビ','ブ','ベ','ボ',
'パ','ピ','プ','ペ','ポ',
'マ','ミ','ム','メ','モ',
'ヤ', 'ユ', 'ヨ',
'ラ','リ','ル','レ','ロ',
'ワ','ヰ', 'ヱ','ヲ',
'ン'
]
f = open('kradfile.utf8')
radicals = {}
for line in f.readlines():
if line.startswith('#'):
continue
kanji, parts = line.split(':', 1)
radicals[kanji.rstrip()] = parts.split()
f.close()
f = open('kanjidic.utf8')
dic = {}
f.readline() # skip header
for line in f.readlines():
line_s = line.split()
on = []
kun = []
on_kun_done = False
trad = ''
for i, elem in enumerate(line_s[2:]):
if elem[0] == 'T':
on_kun_done = True
continue
if elem[0] == '{':
trad = ' '.join(line_s[2+i:])
break
if on_kun_done or ord(elem[0]) >= ord('A') and ord(elem[0]) <= ord('Z'):
continue
for kana in elem.decode('utf-8'):
kana_utf = kana.encode('utf-8')
if kana_utf in katakana:
on.append(elem)
break
if kana_utf in hiragana:
kun.append(elem)
break
dic[line_s[0]] = {'on': on, 'kun': kun, 'trad': trad}
def break_text(text):
if not text:
return ''
words = text.split()
text = []
for i in range(0, len(words), 6):
text.append(' '.join(words[i:i+6]))
text = '<br/>'.join(text).replace('&','&')
return text
print 'digraph K {'
print ' node[fillcolor=gold,style=filled,shape=egg]'
for kanji, desc in kanji_to_learn.items():
dic_info = dic[kanji]
on_kun = ['<font color="red">%s</font>' % break_text(', '.join(dic_info['on' ])) if dic_info['on' ] else '']
on_kun += ['<font color="blue">%s</font>' % break_text(', '.join(dic_info['kun'])) if dic_info['kun'] else '']
kanji_info_str = ' %s [label=<<b>%s</b><br/>%s<br/>%s%s>]' % (kanji, kanji, break_text(dic_info['trad']), '<br/>'.join(on_kun), ('<br/><i>%s</i>' % break_text(desc) if desc else ''))
for part in radicals.get(kanji, []):
if kanji != part:
kanji_info_str += '; %s -> %s' % (part, kanji)
print kanji_info_str
print '}'
Example of usage:
% ./kanji.py > /tmp/kanji.dot
% fdp -Tpng /tmp/kanji.dot > kanji.png
% feh kanji.png